블록체인 데이터베이스, 컨트랙트로 구현한 테이블형 저장소 설계
컨트랙트를 테이블처럼 쓰는 블록체인 데이터베이스 설계. Post·Auth·Relayer·Subscriber·Visitor·YouTube 저장소 구조와 주소/인증 전략까지 한 번에 정리.
컨트랙트를 테이블처럼 쓰는 블록체인 데이터베이스 설계.
Post·Auth·Relayer·Subscriber·Visitor·YouTube 저장소 구조와 주소/인증 전략까지 한 번에 정리합니다.
TL;DR
- 컨트랙트 1개 = 테이블 1개로 보고 설계합니다.
- 온체인은 “확정 가능한 원장(Write)”에 강하지만, “쿼리(Read)”는 약합니다.
- 그래서 쓰기(온체인 확정) / 읽기(오프체인 인덱싱) 를 분리해야 서비스화가 가능합니다.
- 테이블 간 조인은 체인에서 하지 않고, 이벤트(Log) → 인덱서/서버에서 결합합니다.
- 민감 정보는 절대 원문 저장하지 않고 해시/암호화만 온체인 원칙으로 갑니다.
왜 블록체인을 DB처럼 쓰려 했나
중앙화 DB는 편리하지만 다음 한계가 있습니다.
- 기록의 출처/변경 이력/검증 가능성은 결국 “운영자 신뢰”에 의존합니다.
- “내가 만든 기록이 진짜인지”를 제3자가 검증하려면 별도의 증명 구조가 필요합니다.
- 운영 비용(서버/DB/백업/권한/감사)을 계속 안고 가야 합니다.
반대로 블록체인은 불변성·투명성·검증 가능성을 제공하지만,
- 스키마/쿼리 제약이 크고
- 쓰기 비용(가스)과 프라이버시가 어렵습니다.
그래서 이 글은 “블록체인을 DB처럼”이라는 표현을 ‘테이블형 저장소(Write-Optimized Ledger)’로 쓰되, Read는 오프체인으로 서비스화한다라는 관점으로 정리합니다.
큰 그림: Write(온체인) / Read(오프체인) 분리
제가 실제로 의도한 데이터 흐름은 아래와 같습니다.
- 쓰기(온체인): 유저 서명 → 릴레이어 제출(가스 대납) → 컨트랙트에 기록
- 읽기(오프체인): 이벤트(Log) 인덱싱 → 서비스 DB/캐시 적재 → API로 결합 조회
- 정합성: 핵심 키(address, tokenId, hash)는 온체인에 남겨 “검증 가능성”을 유지
핵심은
- 온체인은 “정답의 원천(Source of Truth)”
- 오프체인은 “빠르고 편한 조회/결합/검색” 으로 역할을 나누는 것입니다.
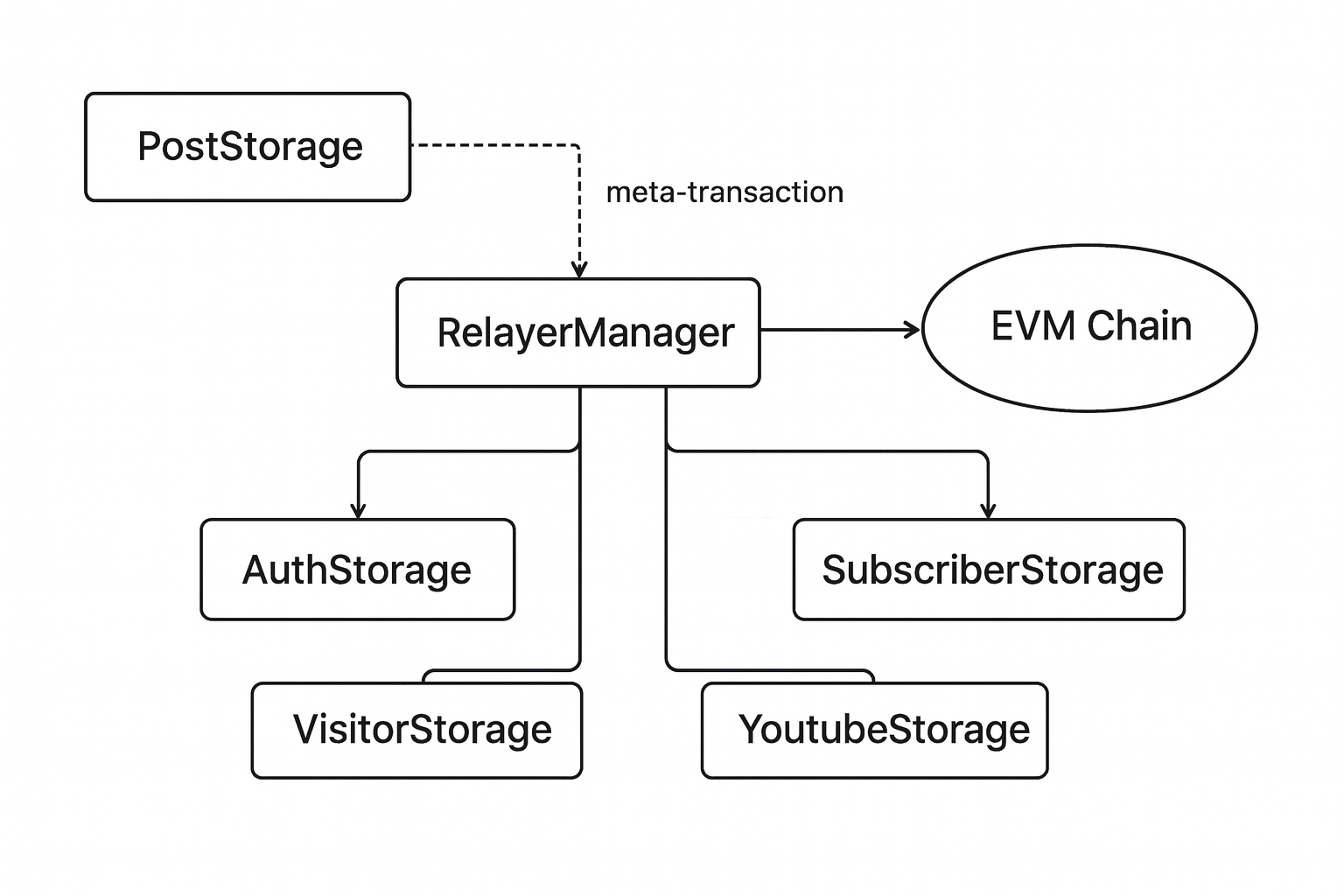
컨트랙트 = 테이블: 저장소 맵핑
핵심 아이디어는 단순합니다.
컨트랙트 1개 = 데이터베이스 테이블 1개
각 테이블은 결국address(혹은 tokenId/해시) 기반의 키로 귀결됩니다.
본 블로그 서비스에서 사용하는 주요 “테이블”은 다음과 같습니다.
| 컨트랙트(테이블) | 역할 요약 | 주요 키/함수 |
|---|---|---|
PostStorage | ERC-721 기반 포스트 저장. 추후 확장 고려(메타트랜잭션) | struct Post, getPosts, tokenId |
AuthStorage | 생체인증(passkey) 기반 인증 데이터 저장소 | addPasskey, DEFAULT_PASSKEY_SLOTS |
RelayerManager | 가스 대납 릴레이어 풀 관리/검증 | onlyRelayer, assertRelayer |
SubscriberStorage | 구독 관계(인증/이메일) 저장 | claimPinCode, addSubscriberEmail, isPinCodeActive |
VisitorStorage | 방문자 트래킹 데이터 저장 | currentDayId, addHashedVisitor, totalVisitorsOf |
YoutubeStorage | YouTube 영상 ID 보관(게시판 연동) | struct YouTubeVideo, saveVideoFor, updateVideoFor |
주의: 테이블 간 조인은 체인 레벨에서 직접 수행하지 않습니다.
조회는 인덱서/서버에서 결합하고, 정합성은 온체인 키(address, tokenId, hash)로 보장합니다.
“테이블 설계”를 위한 규칙 6가지
온체인 테이블을 설계할 때 제가 계속 지키려 한 규칙입니다.
- 키를 먼저 정한다
- 무엇으로 unique를 보장할지:
address,tokenId,bytes32 hash,(dayId, hash)등
- 쓰기 단위는 작게
- 한 트랜잭션에서 너무 많은 스토리지 변경을 하지 않기(가스 급증/실패 리스크)
- 쿼리는 체인에서 하지 않는다
- 정렬/필터/검색은 체인에 맡기지 않고 이벤트 인덱싱으로 해결
- 민감 정보는 원문 저장 금지
- 이메일/IP 같은 건 해시/암호화만 저장(원문은 서버에서 처리)
- 상태를 최소화한다
- “무엇이 진짜로 온체인에 남아야 하는가?”만 남긴다(증명/정합성/권한)
- 업그레이드/이전 전략을 먼저 설계한다
- Proxy로 갈지, 신규 배포 + 마이그레이션으로 갈지 사전에 결정
주소와 인증: 계정 불러오기 전략
모든 데이터는 결국 address로 귀속됩니다. 문제는 일반 사용자가 Hex 주소를 직접 관리하기 어렵다는 점입니다.
제가 선택한 방향은 다음과 같습니다.
- “사용자만 아는 코드 + 생체인증(passkey)”로 파생 규칙을 만들고
- 그 결과로 계정
address를 자동 매핑해 불러옵니다.
즉, 별도의 시드 문구나 복잡한 지갑 UX 없이
“나만의 코드 + 생체인증”으로 서비스를 재현 가능하게 하는 방향입니다.
- passkey 원본은 다중 암호화 후 해시/파생키 형태로 저장
- 실제 비밀키를 온체인에 그대로 보관하지 않는 것을 원칙으로 합니다.
메타트랜잭션과 릴레이어: 쓰기 비용의 현실 해법
블로그 같은 서비스에서 “쓰기”가 늘면 결국 두 가지 문제가 생깁니다.
- 사용자 가스비 부담
- 트랜잭션 동시성으로 인한 nonce 경합(특히 대납 계정에서)
그래서 저는 다음 구조로 정리했습니다.
- 유저는 서명만 한다(EIP-712 등)
- 릴레이어가 트랜잭션을 제출하고 가스비를 대납한다
- 컨트랙트는
RelayerManager를 통해msg.sender가 릴레이어인지 검증한다
운영 팁(제품 관점):
- 릴레이어 풀은 최소 3개 이상으로 분산해 스루풋을 올립니다.
- replay 보호(체인ID·만료시간·도메인 분리)를 넣습니다.
- 대납 정책은 요금제/쿼터 개념으로 설계하고 남용 방지(서명 재사용 제한)를 둡니다.
nonce 충돌과 다중 relayer 선택은 아래 글에서 더 자세히 다룹니다.
데이터 모델과 쓰기/읽기 흐름(서비스화 관점)
-
주소/계정 파생
“개인 코드 + 생체인증” → 파생 데이터 → 계정address -
쓰기(온체인 확정)
유저 서명 → 릴레이어 제출 →RelayerManager검증 → 각 저장소 컨트랙트에 기록 -
읽기(오프체인 서비스화)
이벤트(Log) 인덱싱 → 서비스 DB/캐시 적재 → API에서 결합 조회
(포스트 목록, 방문자 통계, 구독자 목록, 유튜브 연동 등) -
무결성/검증 UX
UI에는 최소 1회 이상 온체인 링크(tx hash, tokenId 등)를 노출해
“검증 가능성”을 시각화합니다.
한계와 운영 상 고려사항
이 구조에는 명확한 한계가 있습니다. 중요한 것은 “한계를 알고 쓰는 것”입니다.
1) 비용(가스)
- 테스트넷에서는 체감이 적지만, 메인넷/트래픽 증가 시 쓰기 비용은 커질 수 있습니다.
- 따라서 온체인에는 “증명/정합성에 꼭 필요한 것”만 남기는 설계가 중요합니다.
2) 프라이버시
- 공개 원장을 쓰는 순간, 민감 데이터는 그대로 노출됩니다.
- 원칙: 원문 저장 금지 + 해시/암호화만 온체인 + 보관 목적 최소화
3) 스키마 진화(업그레이드)
- 컨트랙트는 테이블 스키마와 같아서, 변경이 곧 마이그레이션 문제로 이어집니다.
- Proxy로 갈지, 신규 배포 + 이전 스크립트로 갈지, 초기에 결정해야 운영이 편합니다.
4) 인덱싱 지연/정합성
- 오프체인 인덱서는 지연될 수 있습니다.
- UI에서는 낙관적 업데이트 + 재동기화를 같이 가져가는 편이 안정적입니다.
결론
“컨트랙트를 테이블로 본다”는 관점은
불변성·검증·확장성 사이의 균형을 맞추는 실용적인 절충입니다.
- 온체인은 “확정 가능한 최소 상태”
- 오프체인은 “조회/검색/결합”
이 분리를 명확히 하면, 블록체인을 DB처럼 쓰는 설계도 충분히 서비스화가 가능합니다.